Configuration
Basics
Default Configuration
In the background odata2ts has a defaultConfig,
so that you only need to provide those settings which diverge from that.
Default Configuration
import { ConfigFileOptions, EmitModes, Modes, NamingStrategies } from "@odata2ts/odata2ts";
const defaultConfig = {
sourceUrlConfig: {},
refreshFile: false,
mode: Modes.all,
emitMode: EmitModes.js_dts,
debug: false,
prettier: false,
tsconfig: "tsconfig.json",
converters: [],
skipEditableModels: false,
skipIdModels: false,
skipOperations: false,
skipComments: false,
disableAutoManagedKey: false,
allowRenaming: false,
v2ModelsWithExtraResultsWrapping: false,
v4BigNumberAsString: false,
naming: {
models: {
namingStrategy: NamingStrategies.PASCAL_CASE,
propNamingStrategy: NamingStrategies.CAMEL_CASE,
editableModels: {
prefix: "Editable",
suffix: "",
applyModelNaming: true,
},
idModels: {
prefix: "",
suffix: "Id",
applyModelNaming: true,
},
operationParamModels: {
prefix: "",
suffix: "Params",
applyModelNaming: true,
},
fileName: {
namingStrategy: NamingStrategies.PASCAL_CASE,
prefix: "",
suffix: "Model",
},
},
queryObjects: {
namingStrategy: NamingStrategies.PASCAL_CASE,
propNamingStrategy: NamingStrategies.CAMEL_CASE,
prefix: "Q",
suffix: "",
idFunctions: {
prefix: "",
suffix: "Id",
},
fileName: {
namingStrategy: NamingStrategies.PASCAL_CASE,
prefix: "Q",
suffix: "",
},
},
services: {
prefix: "",
suffix: "Service",
namingStrategy: NamingStrategies.PASCAL_CASE,
main: {
applyServiceNaming: true,
},
collection: {
prefix: "",
suffix: "Collection",
applyServiceNaming: true,
},
serviceResolverFunction: {
namingStrategy: NamingStrategies.CAMEL_CASE,
prefix: "create",
suffix: "serviceResolver",
},
operations: {
namingStrategy: NamingStrategies.CAMEL_CASE,
},
relatedServiceGetter: {
namingStrategy: NamingStrategies.CAMEL_CASE,
prefix: "navTo",
suffix: "",
},
privateProps: {
namingStrategy: NamingStrategies.CAMEL_CASE,
prefix: "_",
suffix: "",
},
publicProps: {
namingStrategy: NamingStrategies.PASCAL_CASE,
},
},
},
propertiesByName: [],
// entitiesByName: [],
}
Configuration Hierarchy
odata2ts exposes different configuration possibilities. Here are all of them and the order in which they are applied:
- default config: sensible defaults provided by
odata2ts - base settings: basic settings which apply to all configured services
- service settings: settings for one specific service,
sourceandoutputmust be specified - CLI options: options provided from command line
The base settings are also some kind of default settings as they have an effect on the generation process of all configured odata services. Base settings are applied on top of the default config.
All settings starting from the services attribute are only valid for a specific service and only applied
for its generation run. Service specific settings may override any default or base setting and allow
for reconfiguring entities and properties.
Some visual aid: A picture can say more than a thousand words...
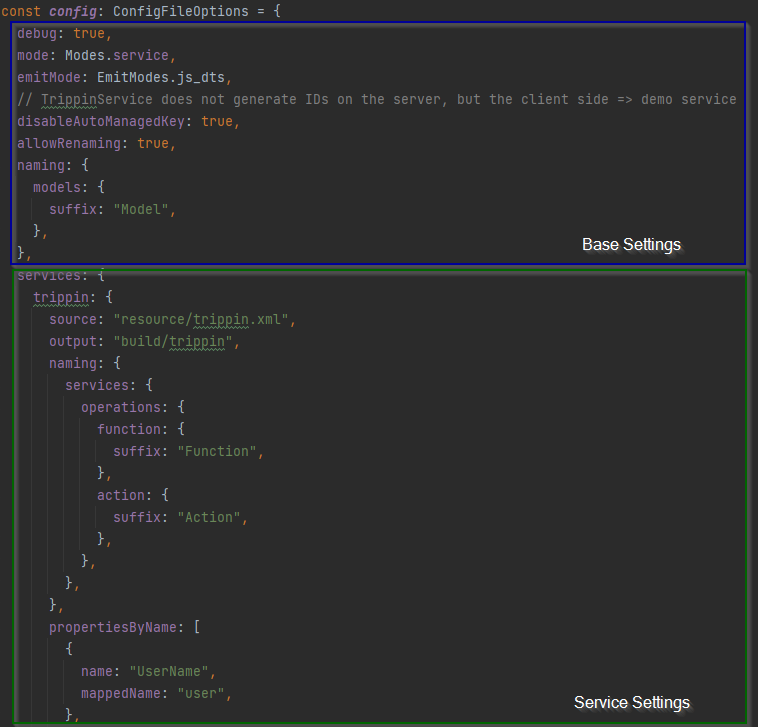
Options specified on the command line always win over other configuration possibilities.
Most base settings are available as CLI options.
Options source and output are required unless the config file is also used
containing appropriate service definitions.
Consider using the config file for all your configurations.
Base Settings
Here is the list of all base settings of the config file. By and large this matches the CLI options.
| Base Setting | Type | Default Value | Description |
|---|---|---|---|
| sourceConfig | UrlSourceConfiguration | {} | Configuration of the request to download the metadata file. See downloading-metadata |
| refreshFile | boolean | false | Download metadata file even if it exists. See downloading-metadata |
| mode | Modes | "all" | Allowed are: all, models, qobjects, service. See generation modes |
| emitMode | EmitModes | "js_dts" | Specify what to emit. ALlowed values: ts, js, dts, js_dts. See emit modes |
| prettier | boolean | false | Use prettier to pretty print the TS result files; only applies when emitMode = ts. See emitting TypeScript |
| tsconfig | string | "tsconfig.json" | When compiling TS to JS, the compilerOptions of the specified file are used; only takes effect, when emitMode != ts. See emitting JS |
| allowRenaming | boolean | false | Allow renaming of model entities and their props by applying naming strategies like camelCase or PascalCase. See renaming properties |
| disableAutoManagedKey | boolean | false | odata2ts will automatically decide if a key prop is managed on the server side and therefore not editable; here you can turn off this automatism. See managed properties |
| debug | boolean | false | Add debug information |
| serviceName | string | Overwrites the service name found in OData metadata. But only makes sense on this level when source & output are specified via CLI options. | |
| skipEditableModels | boolean | false | Don't generate separate models for manipulating actions (create, update, patch). See fine-tuning artefact generation |
| skipIdModels | boolean | false | Don't generate separate models & q-objects for entity ids. See fine-tuning artefact generation |
| skipOperations | boolean | false | Don't generate separate models & q-objects for operations (function or action). See fine-tuning artefact generation |
| skipComments | boolean | false | Don't generate comments for model properties. See fine-tuning artefact generation |
| converters | Array<TypeConverterConfig> | [] | Provide list of installed converters to use. See converters |
| naming | OverridableNamingOptions | see defaultConfig | Configure naming aspects of the generated artefacts. See configuring naming schemes |
| v2ModelsWithExtraResultsWrapping | boolean | false | Add an extra wrapper object around expanded entities in V2. See extra results wrapper |
| v4BigNumberAsString | boolean | false | Retrieve types of Edm.Int64 and Edm.Decimal as string instead of number. See handling big numbers |
Service Settings
There's one more option on the root level of the config file called services.
It represents the entry point into the service settings, which are by nature specific for a single odata service.
The services option is an object, where each key is the internal name of the service
and the value is the configuration (class ServiceGenerationOptions).
These service settings contain all base settings, options source and output (cf. CLI options),
as well as options to reconfigure entities and properties:
| Service Setting | Type | Default Value | Description |
|---|---|---|---|
| source | string | --- | Specifies the path to the metadata source file (EDMX). See setup-and-usage |
| sourceUrl | string | --- | Full URL to the root of your OData service. See downloading-metadata |
| output | string | --- | Specifies the output directory. This folder gets cleaned and overwritten on generation. See setup-and-usage |
| serviceName | string | Overwrites the service name found in OData metadata & controls the main service name. Same as the base setting but on this level it makes sense. | |
| entitiesByName | Array<EntityGenerationOptions> | [] | Match entities by their name and configure them. See entity options |
| propertiesByName | Array<PropertyGenerationOptions> | [] | Match properties by their name and configure them. See configuration by property |
CLI Options
Here is the list of all options available for the command line. As you can see, this largely matches the base settings:
- additionally,
sourceandoutputoptions are available (cf. service settings) - options
skipXXX,convertersandnamingare not available though
| CLI Option | Default Value | Description |
|---|---|---|
--sourceUrl-u | Specifies the full URL to the root of your OData service. See downloading-metadata | |
--source-s | Specifies the path to the metadata source file (EDMX). See setup-and-usage | |
--output-o | Specifies the output directory. This folder gets cleaned and overwritten on generation. See setup-and-usage | |
--refresh-file-f | Download metadata file again, even if it exists. See downloading-metadata | |
--service-name-name | Overwrites the service name found in OData metadata => controls name of main odata service | |
--mode-m | "all" | Allowed are: all, models, qobjects, service. See generation modes |
--emit-mode-e | "js_dts" | Specify what to emit. ALlowed values: ts, js, dts, js_dts. See emit modes |
--prettier-p | false | Use prettier to pretty print the TS result files; only applies when emitMode = ts. See emitting TypeScript |
--tsconfig-t | "tsconfig.json" | When compiling TS to JS, the compilerOptions of the specified file are used; only takes effect, when emitMode != ts. See emitting JS |
--allow-renaming-r | false | Allow renaming of model entities and their props by applying naming strategies like camelCase or PascalCase. See renaming properties |
--disable-auto-managed-key-n | false | odata2ts will automatically decide if a key prop is managed on the server side and therefore not editable; here you can turn off this automatism. See managed properties |
--debug-d | false | Add debug information |
Downloading Metadata
You can let odata2ts download the metadata from your OData service.
You use the option sourceUrl and specify the full URL to the root of your OData service, e.g. https://services.odata.org/TripPinRESTierService.
- the URL is allowed to end with a forward slash
- the URL is allowed to end with
/$metadata
If you require basic auth to access the OData server, then you need to use the sourceUrlConfig option to set
username and password. If you require a more advanced configuration, then you have a custom request configuration
object called custom: It's the request config of Axios.
The source option becomes the storage path of the downloaded file.
- use
prettier: trueto pretty print the file (usesprettierand@prettier/plugin-xmlunder the hood) - the
prettieroption will respect your own prettier setting file - see plugin-xml for further config options
Caching
By default, odata2ts will only download the metadata file, if it does not exist locally.
Use the refreshFile option to force the download. As this option is also available via the CLI,
you can also append the -f option:
- npm:
npx odata2ts -f - package script
gen-odata:npm run gen-odata -- -f - yarn:
yarn odata2ts -f
Generation Modes
odata2ts is able to produce three different kinds of artefacts:
models: tailor-made TypeScript types for entities, complex types, entity Ids and what notqobjects: powerful q-objects to leverage the type-safe and fluent query builderservice: full-fledged, domain-savvy OData service capable of type-safe queries, CRUD operations and more
Each artefact type depends on the existence of the former artefact type. So you can either generate 1) only models, 2) q-objects and models or 3) services, q-objects and models.
You control this aspect of the generation process with the mode setting,
which has an enum representation in the config file (import { Modes } from "@odata2ts/odata2ts").
Fine Tuning Artefact Generation
If you're only interested in models or qobjects, you might want to skip the generation of
certain artefacts. The following options are available as base-settings:
- skipComments:
- dispense with comments for each model property
- skipEditableModels:
- don't create entity representations needed for create, update and patch operations
- skipIdModels:
- don't create types representing the ID of each entity type
- don't create q-id functions, helpful for formatting and parsing entity paths
- skipOperations:
- don't create types representing function or action parameters
- don't create q-functions or q-actions which help to handle those operation calls
Emit Modes
odata2ts supports generating JS / dts or TypeScript files. You control this with the emitMode option,
which has an enum representation in the config file (import { EmitModes } from "@odata2ts/odata2ts").
By default, JS & dts files are emitted.
Emitting Compiled JS / dts
Since the generation process only needs to run when your OData service changes (and therewith its metadata), it makes sense to compile the generated stuff to JS / dts at that moment. This unburdens your TS compiler when developing your app, as it is not required to compile the generated code.
By default, odata2ts tries to use the tsconfig.json at root level for compilation.
You can specify the path to your TS config file via the option tsconfig.
You can also configure to produce only JS or only DTS files, whatever that use case may be.
Emitting TypeScript
When setting the emitMode to TypeScript, you will need to include the output folder for TypeScript.
The easiest route would be to point the output directory to something like src/generated/trippin,
assuming that src is included in your TS config.
However, a cleaner approach would be an own directory like gen*src/trippin and the inclusion
of the gen-src folder in your tsconfig.json.
odata2ts allows to prettify the generated TS files via prettier.
When installed and configured, you just set the option prettier to true.
Types and Converters
OData defines its own primitive data types: Edm.* (e.g. Edm.String or Edm.Boolean).
The JSON representation for each type is defined by the V2 and V4 OData specifications.
Without any converters odata2ts adheres to the appropriate specification.
| OData Type | V2 Type | V4 Type | Example | Description |
|---|---|---|---|---|
Edm.String | string | string | "Test" | |
Edm.Boolean | boolean | boolean | true | |
Edm.Byte | string | number | V2: "1"V4: 1 | |
Edm.SByte | string | number | ||
Edm.Int16 | number | number | 3 | |
Edm.Int32 | number | number | 222 | |
Edm.Int64 | string | number | ||
Edm.Single | string | number | ||
Edm.Double | string | number | ||
Edm.Decimal | string | number | ||
Edm.Duration | - | string | "P12DT12H15M" | ISO 8601 Duration |
Edm.Time | string | - | "PT12H15M" | ISO 8601 Duration, restricted to the time part |
Edm.TimeOfDay | - | string | "12:15:00" | ISO 8601 Time |
Edm.Date | - | string | "2022-12-31" | ISO 8601 Date |
Edm.DateTime | string | - | "/Date(123...)/" | completely custom format: Unix time stamp with offset in minutes |
Edm.DateTimeOffset | string | string | "2022-12-31T12:15:00Z""2022-12-31T12:15:00+01:00" | ISO 8601 Date and Time |
Edm.Binary | string | string | base64 encoded string |
Type Converters
odata2ts acknowledges the fact that this kind of shallow data representation (string of some format)
is far from being optimal and offers converters to use different data types.
Available converter packages:
- v2-to-v4: dispense with weired
DateTimeformats and numericstrings - common: facilitate JS
Dateorbigint - luxon: use Luxon's
DateTimeandDurationtypes - ui5-v2: use same types as UI5's V2 ODataModel
Roll Your Own Converter
Outline:
- individual converters reside in a converter package which is an own JS module with its own
package.json - each converter implements interface
ValueConverter<x, y> - follow conventions regarding package structure and exports
See Creating You Own Converter Module.
Naming
Since odata2ts generates multiple artefacts out of a single entity or complex type,
naming schemes are required, to discern, for example, a Person (model)
from its magical counter-part QPerson (q-object). These "naming schemes" permeate all aspects of the
generated artefacts and are configurable.
However, first we need one simple concept: Naming strategies.
Naming Strategies
We employ one general concept labelled "naming strategy" and mean by that a certain way to format a given string regarding its individual parts. The following naming strategies are supported:
- pascal case: "foo bar" => "FooBar"
- camel case: "foo bar" => "fooBar"
- capital case: "foo bar" => "FOO_BAR"
- snake case: "foo BAR" => "foo_bar"
We rely on the change-case library here (actually we only use the mentioned packages not the whole library, but it's a nice overview).
Naming strategies guarantee consistency without sacrificing semantics, since the original term lives on.
Configuring Naming Schemes
In general, most naming schemes consist of the following settings:
- prefix
- suffix
- namingStrategy
Here is an example showing the default naming options for models:
const namingConfig = {
naming: {
models: {
namingStrategy: NamingStrategies.PASCAL_CASE,
propNamingStrategy: NamingStrategies.CAMEL_CASE,
editableModels: {
prefix: "Editable",
suffix: "",
applyModelNaming: true,
},
idModels: {
prefix: "",
suffix: "Id",
applyModelNaming: true,
},
operationParamModels: {
prefix: "",
suffix: "Params",
applyModelNaming: true,
},
fileName: {
namingStrategy: NamingStrategies.PASCAL_CASE,
prefix: "",
suffix: "Model",
},
}
}
}
If the special property applyModelNaming is true, then prefix and suffix of the parent property
are added as well. For example, a common convention is to add "I" in front of interfaces,
which would be as easy as this:
const namingConfig = {
naming: {
models: {
prefix: "I",
suffix: ""
}
}
}
Because applyModelNaming is by default set to true, all related models would be prefixed in
this way: IPerson, IEditablePerson, IPersonId.
As best practice, always override prefix and suffix, when you want to set one or the other.
Managed Properties
Some properties are managed by the server, most notably ID fields:
The server is responsible for generating a unique identifier for each new entity.
Other examples are fields like createdAt or modifiedBy which are
automatically handled by the server or database.
In all of these cases, the client is not allowed to directly manipulate those managed fields. This fact needs to be reflected in the editable model versions, which are used for create, update, and patch actions: All managed fields need to be filtered out.
Automatism
odata2ts employs the following automatism:
Single key fields (the key of the entity is composed of one single field), like ID, are marked as managed,
while each field of a complex key (the key of the entity is composed of multiple fields) is regarded as unmanaged.
If you want to turn off that automatism, use the option disableAutoManagedKey.
Some servers advertise this information via annotations. However, this is a server specific implementation and not covered by the OData specification.
Currently, annotation processing is not supported by odata2ts,
but already on the roadmap.
Configuration by Property
You can and maybe have to configure properties manually to mark them as managed.
See property options.
Reconfiguring Entities and Properties
odata2ts offers some options to reconfigure entities and properties of your OData service:
- apply naming strategies for their names: see renaming entities and properties
- use different names by manually specifying them
- override faulty key definitions for entities
- mark properties as
managedto prevent any client side manipulation of them
The last three options are realized via the settings propertiesByName or entitiesByName
which work in the same way. Both expect an array of objects, whereby each object must have
a name property. This name property must match the entity or property name as it is stated
in the EDMX of the OData service.
The name property can also be a regular expression which matches the whole name
(internally we add "^" to the beginning and "$" to the end of the expression).
Renaming Entities and Properties
By default, odata2ts uses the names as they are provided by the OData service.
Usually it's a good thing to have frontend and backend aligned on entity and property names. There's some middle ground, however: Allow to apply naming strategies. So you use the same names, but allow for adjustable casing (e.g. camel-case or pascal-case). This makes things more natural from a JS perspective.
Via the setting allowRenaming (false by default) you allow odata2ts to apply
the configured naming strategies for entity (default: pascal-case) and property names (default: camel-case).
Entity Options
Currently, you have two options here:
- rename entities (regular expressions are supported)
- fix faulty key specifications
const config = {
services: {
myService: {
source: "...",
output: "...",
entitiesByName: [
{
name: "SOME_CrazY_NAME",
mappedName: "saneName"
},
{
name: /SOME_PREFIX_(.*)/, // match by regular expression
mappedName: "$1" // replace name by captured group => thereby remove the prefix
},
{
name: "FaultyEntity",
// fix faulty key specification by manually naming all the key properties
keys: ["Id", "Version"]
}
]
}
}
}
Renaming entities this way is independent of the allowRenaming setting
(see renaming entities and properties).
Property Options
You have two options here:
- rename properties (regular expressions are supported)
- mark properties as managed (cf. managed properties)
const config = {
services: {
myService: {
propertiesByName: [
// simple renaming
{
name: "someWeiredPropName",
mappedName: "saneName"
},
{
name: /id/i, // uses case: insensitive regular expression to find "ID", "id", "Id", ..
mappedName: "id", // rename them consistently
managed: true, // mark them as managed
},
// use a list of fields to mark them all as managed
...["createdAt", "createdBy", "modifiedAt", "modifiedBy"].map((prop) => ({ name: prop, managed: true }))
]
}
}
}
Renaming properties this way is independent of the allowRenaming setting
(see renaming entities and properties).
V4 Big Number Handling
Numbers of type Edm.Int64 and Edm.Decimal are represented as number in V4.
However, these numbers might not fit into JS' number type, which might result in precision loss.
OData offers a special IEEE754 format option to get those types as string instead to prevent any
precision loss. So if you're handling very large or very small numbers (JS roughly supports 15 digits),
then you should set the config option v4BigNumberAsString to true.
Activating this option affects the type generation and will use string for Edm.Int64 and Edm.Decimal.
All requests are executed with the accept header set to application/json;IEEE754Compatible=true.
Additionally, when sending data the very same value will be set for the content-type header.
Now you can use converters to get a better suited data type: See Big Number Converters.
The OData V4 specification allows to set this format option on a per-request basis.
odata2ts handles this format option globally, because the type generation process is affected.
V2 Extra Results Wrapper
The OData V2 specification is sometimes quite ambiguous or not detailed enough. This is especially true when it comes to the JSON representation of expanded collections. Because of that two variants exist in the wild:
export interface Category {
// this is the default typing by odata2ts
products: Array<Product> | DeferredContent;
}
export interface Category {
// this is with the extra results wrapper
products: { results: Array<Product> } | DeferredContent;
}
You need to add a special configuration if
- your OData service adds this extra results wrapper
- you're only generating types
You simply set the base setting v2ModelsWithExtraResultsWrapping to true and the second version gets generated.
This setting only takes effect, when mode=Models and the OData service in question is V2.
If you're generating more than just the types, then odata2ts already got you covered.
It changes this detail at runtime and converts the second version to the first version on-the-fly.
So it works out-of-the-box.